How Should We Think About Security in the Agent Era?
For a long time, AI security was mostly discussed around models, data, and outputs. Topics like prompt injection, data poisoning, model theft, and sensitive data disclosure were at the center of these conversations. But as generative AI is moving toward agentic systems, the security question is also changing. Now the issue is not only what the model produces, but also which tools it can access, which data it can use, what actions it can start, and how all of this can be controlled. Google’s SAIF 2.0 appears at exactly this turning point. It expands the classic AI security framework to include the risks of autonomous agent systems.
Google describes SAIF 2.0 as a continuation of its Secure AI Framework, but it is more than a simple version update. This new stage focuses strongly on secure agents. Google clearly says that agents are different from other AI systems because they can take autonomous actions. Because of this, they need their own risk and control model. In this sense, SAIF 2.0 is not just about protecting AI models. It is about building AI systems that people can trust.
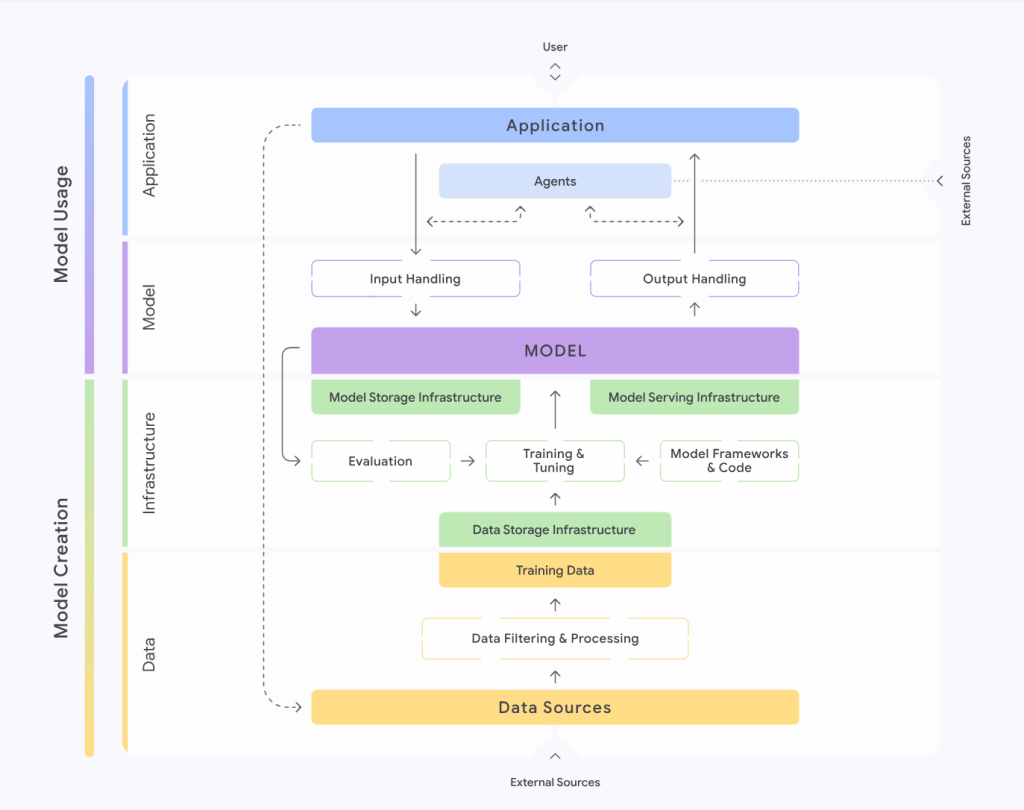
One of the most important parts of SAIF 2.0 is that it does not look at security only from the model layer. The framework still keeps its main structure around four areas: data, infrastructure, model, and application. At the same time, it connects these areas to the full AI development lifecycle, including data collection, training, evaluation, model serving, user interaction, tool use, model integration, and application testing. This means SAIF 2.0 tells us something very important: agent security is not a small part of model security. It is a system-wide security problem.
That is why I think the best way to explain SAIF 2.0 is this: agents are not just LLMs that can talk. They are LLMs that can decide, use tools, and create real results. From a security view, this changes everything. A normal generative model may give a wrong answer, which is mostly a quality problem. But if an agent uses the wrong tool, sends sensitive data to the wrong place, or takes action on behalf of a user, this becomes a direct security and governance issue.
Another strong part of SAIF 2.0 is the way it explains risk. SAIF does not only list risks one by one. It also tries to show where a risk enters the system, where it becomes visible, and where it can be reduced. This approach is very valuable for security teams because it turns AI risk into something more practical. A risk may start during data collection, become visible during model serving, and be reduced at the application layer. This creates a strong bridge between traditional application security and AI security.
This agent-focused view also makes some risks much more serious. For example, prompt injection is no longer only about changing the model’s behavior. In agent systems, it can also affect tool usage, external system access, and automated decision-making. In the same way, sensitive data disclosure becomes more dangerous because agents often have access to a wider data surface. SAIF also highlights “inferred sensitive data,” which means that even if a model does not directly reveal training data, it may still make sensitive conclusions based on patterns it has learned. This reminds us that AI security is not only about protecting data, but also about controlling what the model can infer.
One of the most critical ideas in SAIF 2.0 is the focus on rogue actions. A standard LLM may generate advice, but an agent can turn that advice into action. Because of this, the security question changes from “Is the output correct?” to “What permissions does this system have, when can it use them, and where does human control begin?” This is, in my opinion, one of the clearest messages of SAIF 2.0. As AI systems become more autonomous, security must focus more on authority, control, and action.
This creates an important lesson for security teams. SAIF 2.0 shows that it is not enough to treat an AI agent like a smart product feature. An agent creates a new runtime layer. In this layer, we need to think again about tool permissions, data access boundaries, confirmation flows, safe output rendering, logging, and monitoring. These are not fully new ideas, but they must now be adapted to AI systems that can make decisions and perform actions.
I think one of the most valuable parts of SAIF 2.0 for companies is that it gives a clearer answer to the question: who is responsible for AI security? In agent systems, risk does not appear only inside the model team’s work. Data teams, platform teams, application developers, security architects, and governance teams all become part of the same picture. A risk may begin in data intake, grow during model training, become visible in serving, and finally lead to damage at the application layer. This shows that AI security is not the job of one team. It is a cross-functional discipline.
Another important point is that SAIF 2.0 is useful not only for security teams, but also for product teams. It presents security not as a checklist that is added at the end of development, but as an engineering discipline that must be considered during design. This is especially important for agent systems. The idea of “build it first, secure it later” is much more dangerous here. Product teams need to decide early which tools an agent can use, which data it can access, which decisions it can make alone, and when it must ask for user approval.
My own view is that the real strength of SAIF 2.0 is that it breaks the habit of thinking about AI security only in a model-centered way. In the agent era, the main attack surface is often not inside the model itself, but in the systems connected to it. What calendar can it access? Which emails can it read? Which files can it export? Which APIs can it call? Which decisions can it make on behalf of the user? These questions are now at the heart of AI security. That is why SAIF 2.0 matters so much. As autonomy increases, security stops being only about content safety and becomes more about permission safety and action safety.
In the end, SAIF 2.0 represents a new stage in AI security. Older risks such as data poisoning, model exfiltration, reverse engineering, and sensitive data disclosure are still important. They have not disappeared. But agentic systems add a new layer on top of them: action. Once action enters the picture, the security problem becomes more real, more operational, and more serious. For this reason, SAIF 2.0 should not be read only as a Google security document. It should be seen as a roadmap for how security thinking must evolve in the age of AI agents.